ParisHacker Mai 2015
13 May 2015Le dernier meetup ParisHacker avait lieu, une fois de plus, à Tektos. Il y avait une centaine d'inscrits sur meetup, mais on était au final à peine une vingtaine, sans doute la faute à la veille d'un week-end prolongé. En tout cas, c'était dommage.
On a eu le droit à trois talks, entrecoupés de pause pour prendre des bières et du fromage. D'abord, Vincent nous a parlé des challenges rencontrés à Algolia pour avoir un réseau distribué, ensuite Laurent nous a parlé de Couchbase Mobile et Emmanuel de Diffbot.
Challenges of Distributed Search Network
Déjà, je dois dire que bossant avec Vincent, j'avais déjà vu son talk quelques heures plus tôt. Du coup, j'étais un peu moins assidu pour prendre des notes, je vais quand même tenter d'en retranscrire le plus important.
Vincent travaille donc à Algolia, et même s'il travaille essentiellement sur les aspects front-end d'Algolia, il nous a quand même donné une idée plus générale de ce qu'il se passe sur un service en SaaS comme Algolia.
Sa présentation était en trois parties, d'abord une explication de ce qu'implique de faire de la recherche sur le net, ensuite ce que propose Algolia et finalement quelques tips et REX.
Search Engine ≠ Database
Déjà, la recherche sur le net, on n'y fait plus réellement attention, mais on passe la majorité de notre temps à faire des recherches sur Google pour trouver ce qu'on recherche. On commence quasiment toutes nos sessions de browsing par une session de recherche, mais il s'empêche que les algos et l'infrastructure qui tournent derrière sont très complexes.
On remarque aussi que bien souvent, la pertinence des résultats de recherches de Google est bien supérieure à la pertinence des résultats au sein même d'un site, si bien qu'on en vient à faire quelque chose de complètement absurde mais qui marche très bien : rechercher sur Google pour trouver quelque chose dans un site en particulier. Mais on reviendra là dessus plus tard, quand on parlera d'Algolia précisément.
Bon, déjà éliminons quelques misconceptions. Un moteur de recherche n'est pas une base de données. Dans une base de données, on fait des tas d'opérations (INSERT, UPDATE, DELETE, SELECT, etc) et on a un langage de query qui permet d'exprimer des demandes complexes.
Par contre, dès qu'on veut faire une recherche full text, on se retrouve avec des opérations couteuses, comme le LIKE %FOO% qui, en plus de devoir scanner l'ensemble des items, ne sait pas gérer les typos ou les pluriels.
Par contre, dans un moteur de recherche, on ne doit s'occuper que d'un seul type d'opération : la recherche. Pas besoin de langage aussi complexe que du SQL, on se concentre sur une seule opération et on l'optimise pour le use-case le plus commun : la recherche full text.
Indexing and Querying
Gérer un moteur de recherche nécessite deux parties. D'abord on indexe, ensuite on recherche. L'indexation consiste à enregistrer les documents de manière optimisée pour le search. Quand ensuite vient la recherche, en plus de retourner l'ensemble des documents qui correspondent aux termes envoyés, on doit aussi les classer par pertinence.
L'indexation peut se vulgariser assez facilement. Pour chacun des documents à indexer on liste les mots qui le composent, puis on fait une liste inversée de ces mots. Ainsi, on a une structure simple clé/valeur qui pour chaque clé (mot) comprends une liste de valeurs (les documents qui contiennent ce mot). Un peu comme un sommaire à la fin d'un livre de cuisine qui va pour la ligne tomate, indiquer toutes les pages de recettes qui utilisent des tomates. Et les résultats de recherche pour foo bar sont donc simplement l'intersection des résultats de recherche de foo et de bar.
Ça, c'est pour la partie théorique et simplifiée. En vérité, la structure qui contient cette relation terme/document est bien plus compliquée pour gérer les pluriels, les synonymes et les fautes de frappe, mais l'idée sous-jacente reste la même.
Algolia
Maintenant qu'on a vu un peu de théorie pour démystifier la recherche, voyons ce que propose Algolia. Algolia se pose comme un Google à l'intérieur de notre application. Plutôt que d'aller chercher dans un index de pages web, Algolia permet d'aller chercher dans un index de données qui nous sont propres (users, produits, vidéos, whatever). La force d'Algolia réside avant tout dans la vitesse d'exécution.
Le temps entre la pression de la touche par l'utilisateur et l'affichage des résultats sur son écran ne dépasse pas les 50ms (latence réseau comprise). Cette vitesse permet de faire des UI qui affichent les résultats directement quand l'utilisateur tape une nouvelle lettre de son clavier plutôt que d'attendre de devoir lui faire recharger une nouvelle page de résultats. Je ne parle même pas de la manière dont tout cela aide le cerveau humain en lui suggérant des éléments plutôt qu'en le faisant travailler à se souvenir de ce qu'il veut taper.
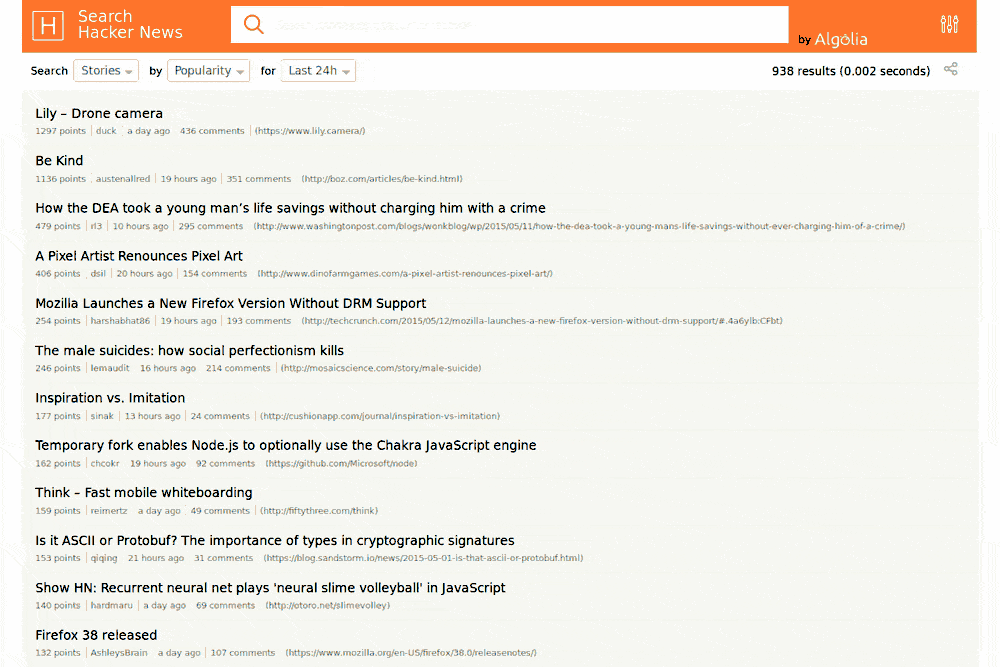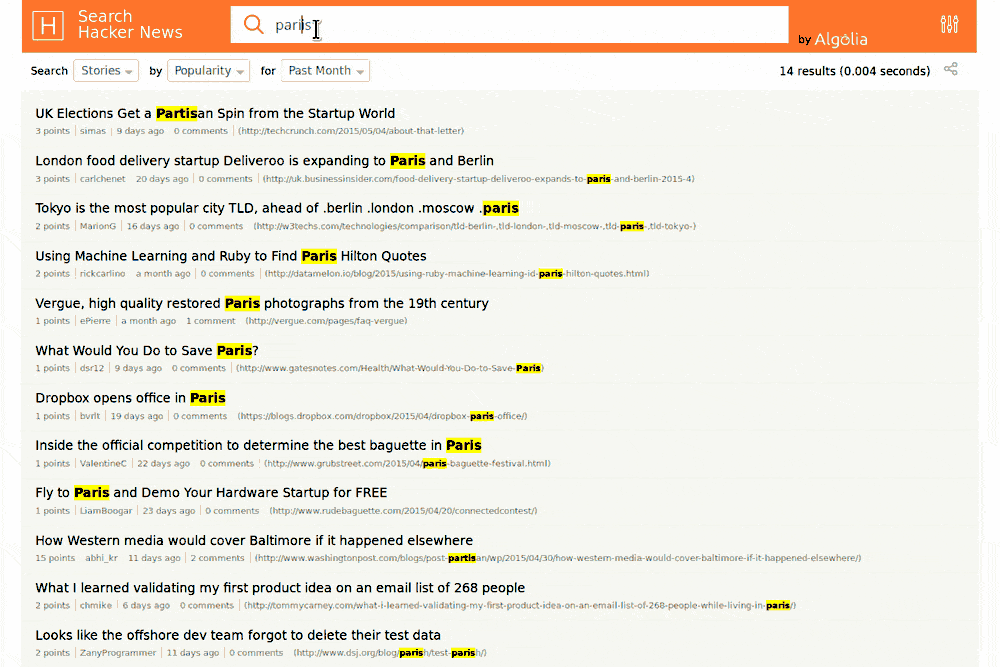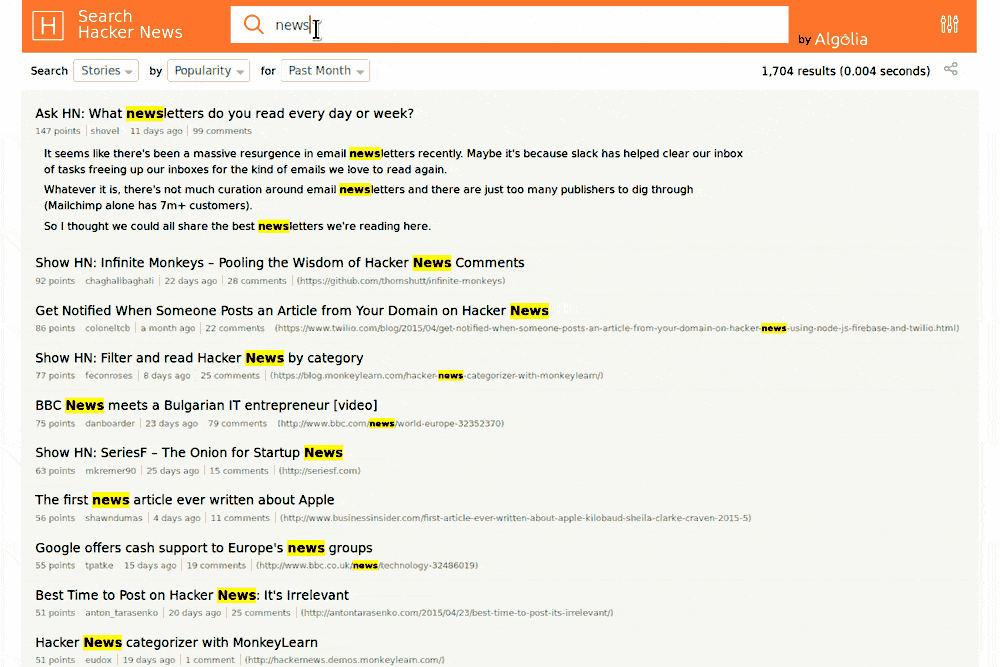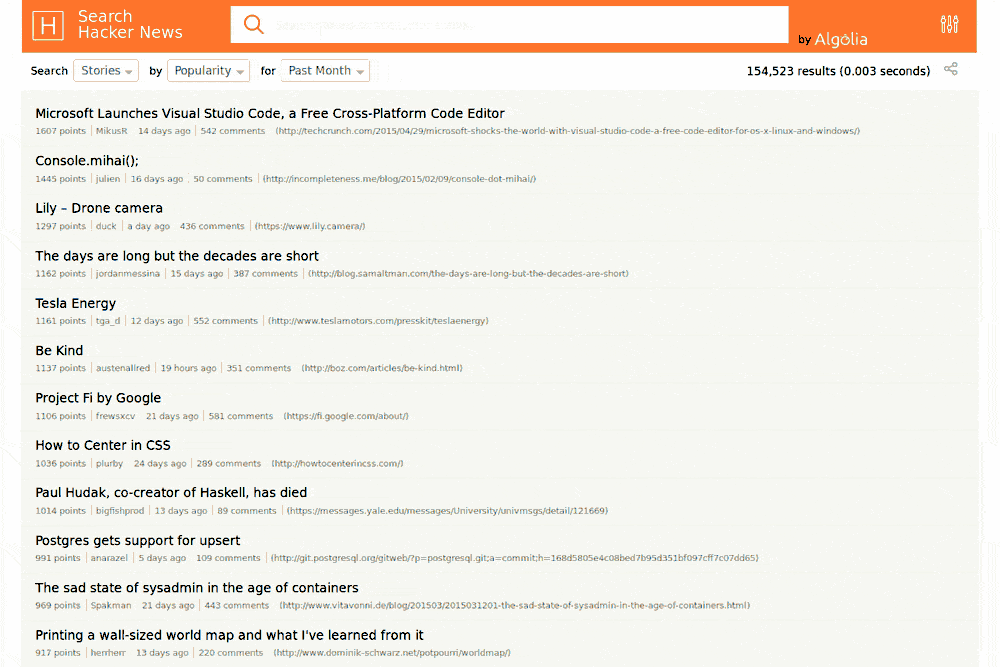
Bref, on a eu une belle démonstration d'Algolia sur HackerNews (spéciale dédicace à ParisHacker). Vincent nous a ensuite parlé du réseau distribué d'Algolia dans 12 datacenters dans le monde et nous a ensuite parlé des trois piliers de la performance qu'Algolia s'efforce d'optimiser : Software, Hardware et Network.
Pour le software, il faut savoir que la première version du moteur d'Algolia était fait sous forme de SDK embarqué dans des applications mobiles. Il fallait donc réussir à tirer profit au maximum des capacités de la machine pour pouvoir créer une expérience de search ultra rapide. On parle là de micro optimisation à la milliseconde. Le code a continué depuis d'évoluer et de s'améliorer et est aujourd'hui inclus directement sous forme de code natif dans les nginx des serveurs Algolia.
Coté Hardware, les serveurs tournent sur du matériel custom, dont les processeurs, la RAM et les SSD sont sélectionnés avec soins. Plusieurs tweaks sont appliqués directement sur le kernel pour avoir aussi les meilleurs rendus, et ce n'est pas le genre de chose qu'on peu faire sur des machines classiques.
Finalement, le gros des pertes de performances venant du réseau, Algolia a misé au maximum sur un réseau distribué de manière à pouvoir être au plus proche des utilisateurs. On a beau faire toutes les optimisation que l'ont peut, il arrive un moment où on ne peut pas faire transiter l'information plus vite que la vitesse de la lumière, donc le seul moyen est de se rapprocher au maximum de l'utilisateur final. En plus de la proximité géographique, il faut faire attention au peering que possèdent les opérateurs où on mets ses serveurs.
Pro Tips
Finalement, Vincent nous a fait part de 10 tips qu'Algolia a appris en mettant au point son infra et qu'ils partagent.
Déjà, il n'existe pas un provider unique et magique qui est présent dans tous les pays du monde avec un formidable débit. AWS c'est cool, mais il n'est pas présent en Inde, en Afrique et dans une bonne partie de l'Asie. Il faut donc utiliser aussi d'autres providers, et dans ce cas il faut essayer d'en avoir le moins possible pour ne pas compliquer les transactions. Aussi, il faut s'attendre à quelques surprises au niveau de la douane, ce n'est pas toujours facile de faire livrer des serveurs dans certains pays et alors il faut attendre plusieurs mois...
Vient ensuite la question du prix. Avec plusieurs providers, la même infra ne coûte pas le même prix dans plusieurs pays. Parfois il n'est pas possible d'avoir la même infra, certains serveurs n'étant pas disponibles, ou alors la tarification est différente. Dans ces cas là, est-ce qu'il faut reporter cette complexité dans la tarification faite à l'utilisateur ou ne proposer qu'un prix unique à l'utilisateur ? Algolia a choisir de masquer toute cette complexité, proposant le même prix à tout le monde.
Proposant une réplication dans 12 datacenters, Algolia a du se pencher sur un système de réplication. Comment faire discuter tout ces datacenters et rendre la recherche distribuée ? La solution la plus simple est souvent la meilleure. Chaque datacenter possède une copie de la donnée et est composé de trois machines. Une de ces machines est un master, sur lequel peuvent se faire les écritures, et les deux autres des slaves qui ne font que de la lecture.
Ensuite, on parle de DNS. Déjà la petite anecdote c'est qu'un .io sera plus lent qu'un .com ou .net. Ayant voulu se la jouer cool, comme toutes les startups, Algolia est initialement parti sur un .io, mais ce TLD étant beaucoup plus récent, il n'y a que 6 serveurs qui font foi pour la résolution de ce TLD alors que .com et .net en ont beaucoup plus.
Algolia utilise la résolution DNS pour sélectionner le datacenter le plus proche de l'utilisateur. Pour cela, il faut un fournisseur qui accepte la geo ip et l'edns. Mais surtout, la résolution DNS est un gros SPOF. Les SDK implémentent donc un mécanisme de fallback si jamais la résolution DNS principale fail, ils vont utiliser un deuxième fournisseur.
Pour s'assurer que tout ceci tourne correctement, Algolia utilise de simples sondes. Ce sont de petits serveurs peu consommateurs, éparpillés dans le monde, qui vont pinguer et exécuter quelques opérations classiques 24/24. Ils envoient leurs données à un master qui affiche l'état du réseau en temps réel sur status.algolia.com.
La fin du talk a été agrémentée de questions et de quelques bières, puis on est passés aux deux autres présentations.
No bars, no problems
Ensuite, Laurent Doguin nous a parlé de Couchbase Mobile.
Aujourd'hui, on est habitué à avoir une connexion à peu près tout le temps. Mais quand elle se dégrade, ou pire, quand on n'a plus de connexion du tout, on se retrouve avec une application qui au mieux est lente et frustrante, au pire ne fonctionne pas du tout et est donc encore plus frustrante.
Si on regarde les raisons pour lesquelles les gens laissent de mauvais ratings aux applications sur les stores, c'est globalement parce que les apps crashent ou sont lentes.
Le problème majeur derrière ça que CouchBase Mobile cherche à résoudre est l'endroit où les données sont stockées. Évidemment, si les données sont stockées sur un serveur distant et qu'on n'a pas de connexion pour y accéder, l'application ne peut pas fonctionner.
Par contre, si on inverse le paradigme et qu'on considère que la source principale de la donnée se trouve directement sur le téléphone de l'utilisateur, alors les applications peuvent travailler en mode offline tout le temps. L'offline devient le mode par défaut et la synchronisation avec un serveur distant devient une opération secondaire, quand la connexion revient.
J'avais déjà vu d'autres personnes attaquer ce problème, comme hood.ie ou PouchDB. Là, Couchbase Mobile nous promets une libraire simple à utiliser, rapide, basée sur du json schemaless et qui prends peut de mémoire. Elle fonctionne sous forme d'évènements et se charge de la synchronisation automatiquement.
Son store est un store de type document, avec un système de clé/valeur versionnées (permettant de gérer les conflits entre plusieurs versions, et laissant à l'utilisateur le soin de gérer manuellement les conflits qui ne peuvent pas être réglés automatiquement).
La suite de la présentation était une démo à base de live coding, mais j'ai complètement décroché.
The Web as a structured database
Ensuite, Emmanuel Charon de Diffbot nous a parlé de leur outil de scraping à base de reconnaissance visuelle.
Leur outil fait du scraping de pages web, mais il ne va pas regarder le code HTML sous-jacent, ni même faire de la reconnaissance d'image, il va à la place simuler un cerveau humain à qui on donne une image, et il va en extraire les informations importantes.
Diffbot est capable d'analyser n'importe quelle page web et d'en ressortir une représentation en JSON en analysant le contenu. Il peut en sortir les commentaires, les images, les tags associés (qu'il déduit depuis le texte, même s'ils ne sont pas directement taggués comme tels). Il fait un peu d'analyse de sentiment (positif/négatif) bien que cette partie ne soit pas encore assez au point pour qu'ils la mettent trop en avant.
Le but de Diffbot est de pouvoir permettre de faire des queries de manière humaines, comme "toutes les chaussures qui ont des commentaires qui les disent confortables" ou "toutes les mentions de untel dans les deux dernières semaines".
Want to add something ? Feel free to get in touch on Twitter : @pixelastic