MiXiT 2017: The Tech Part
20 Apr 2017Here is my second post about the MiXiT conference. The first post was about everything non-tech at MiXiT, so this one will go the more tech route. MiXiT is a multi-track conference, with non-tech keynotes and random talks (where you're assigned a random room to see a talk you don't known anything about). You can spend two whole days without seeing a single tech talk if you'd want.
Streaming API
My first tech talk was by Audrey Neveu, about realtime applications. She did an improved version of the one I saw at BestOfWeb last year. Unfortunately, the gods of live coding were not with her. The drone she was supposed to fly refused to connect to the wifi. She had to raise and lower it by hand, which was funny, but not exactly what was planned.
She talked about the importance of real time. We react differently to things that moves. Our reptilian brain is wired in such a way that if it moves, it's either:
- Something we can eat
- Something that can eat us
Either way, better keep an eye on it.
Same principle applies to screens today. We're drawn to screens where things are moving. We expect data to update itself without any interaction from us. We all know the frustration of having to press the Refresh button. The Refresh button is the bane of all interactivity.

We invented the SPA (Single Page Applications) as a way to develop apps that didn't require a Refresh button. The front-end is made of HTML/CSS while the data is fetched through JavaScript calls to APIs in the background. By adding a bit of polling on a regular interval, we can make data update itself.
This is not real time though, as we only get data when we ask for it, but it's a good start. If we poll data in short interval (~1 second) we can make it look like real time. But this creates a lot of overhead. Even without such a short polling interval, most of the requests are wasted (up to 98.5% according to Zapier), meaning that the data we got is the same than our previous call. Nothing changed.
Sending so many requests has a cost. You have to open a new connection to the server each time, get the answer, then start again. Creating connection has a cost, both for the client and the server. That's when long polling was invented.
Long polling is a hack around the classical client/server achitecture where the server does not actually closes the connection. Instead, it keeps it open, and sends data when it's updated on its side. It's a clever hack, but it does not scale. Servers are not meant to maintain that many open connections at once.
Actual realtime solution exists, though. The more common are WebSockets and Server Sent Events (SSE for short). They are both well supported by browsers, but have different use-cases.
WebSockets uses a bidirectional channel to send events between the client and the server. It's a specific protocol on top of HTTP, so you might have to update your firewall rules to use it (which might be hard to do in some settings). It's incredibly useful if you need to build a realtime app with data flowing in each direction, like for a chat or a video game.
Most of the time though, what you need is to react to events sent from the server. Actions done by the users can still go through a classical GET request. For that use-case, SSE are a much better approach. They are classical HTTP requests sent from the server to the client, and you can react on them like you would do for any event in JavaScript. It's well supported (except by IE) and does not require changes to firewall rules.
We're so used to have real time in our applications, that not having it will be like having a search bar that asks you to press Enter to get results. We're so spoiled by applications like Amazon, Facebook or Google that we expect everything to be dynamic and to react to us instantly.
CSS Is Awesome
Then, Igor Laborie showed to a packed room some nifty CSS tricks. I've been using CSS extensively myself, but I was happy to discover some new tricks.
Following the Rule of Least Power, his goal was to show that CSS was powerful enough that you often don't need JavaScript nor pre-processors at all. His talk was a succession of small tricks to achieve more and more complex effects. Here is a small sample:
- By using
currentColorand alpha-transparency it's often possible to style a complete element with one simple color without requiring variables. - Using
::beforeand::afterpseudo-elements, you can add content, and by using UTF-8 characters you can even draw more advanced shapes. - Using background color, borders, outlines, box-shadows and before/after elements, you could draw many, many, many colors on one single element.
- Using a
contentspanned on several lines using\a, clever UTF-8 chars and an animation let you create a nice loader. - Linking a
labelto itscheckboxon top of the page let you add a global state to the page. - Adding a
skeweffect on a rectangle with someborder-radiuscreates the perfect tab shape. <details>and<summary>are default HTML5 tags for a collapsible, anddialogcan be used for modals (along with the full-screen backdrop withpointer-events: none.
Being a developer after 40
Adrian Kosmaczewski then talked about what it means to be a developer at age 43. He was talking about what changed and didn't change in all his years as a developer, and he did so with a lot of humor.
Everything has changed in 20 years. We now have smartphones in our pockets more powerful than the most powerful computer we could dream of. We can stream video and talk with people on the other side of the globe in realtime. We have access to all the knowledge of the world for free. We have e-cigarettes and e-books, self driving cars and connected fridges.
But let's not forget the large number of languages, frameworks and technologies that didn't work. From Angular to Sencha Touch, PDA and Mini-Discs, many tech were supposed to be the next big thing but ended up being the next big nothing. They went crashing down from the Peak of Inflated Expectation right into the Trash Heap of Failures.
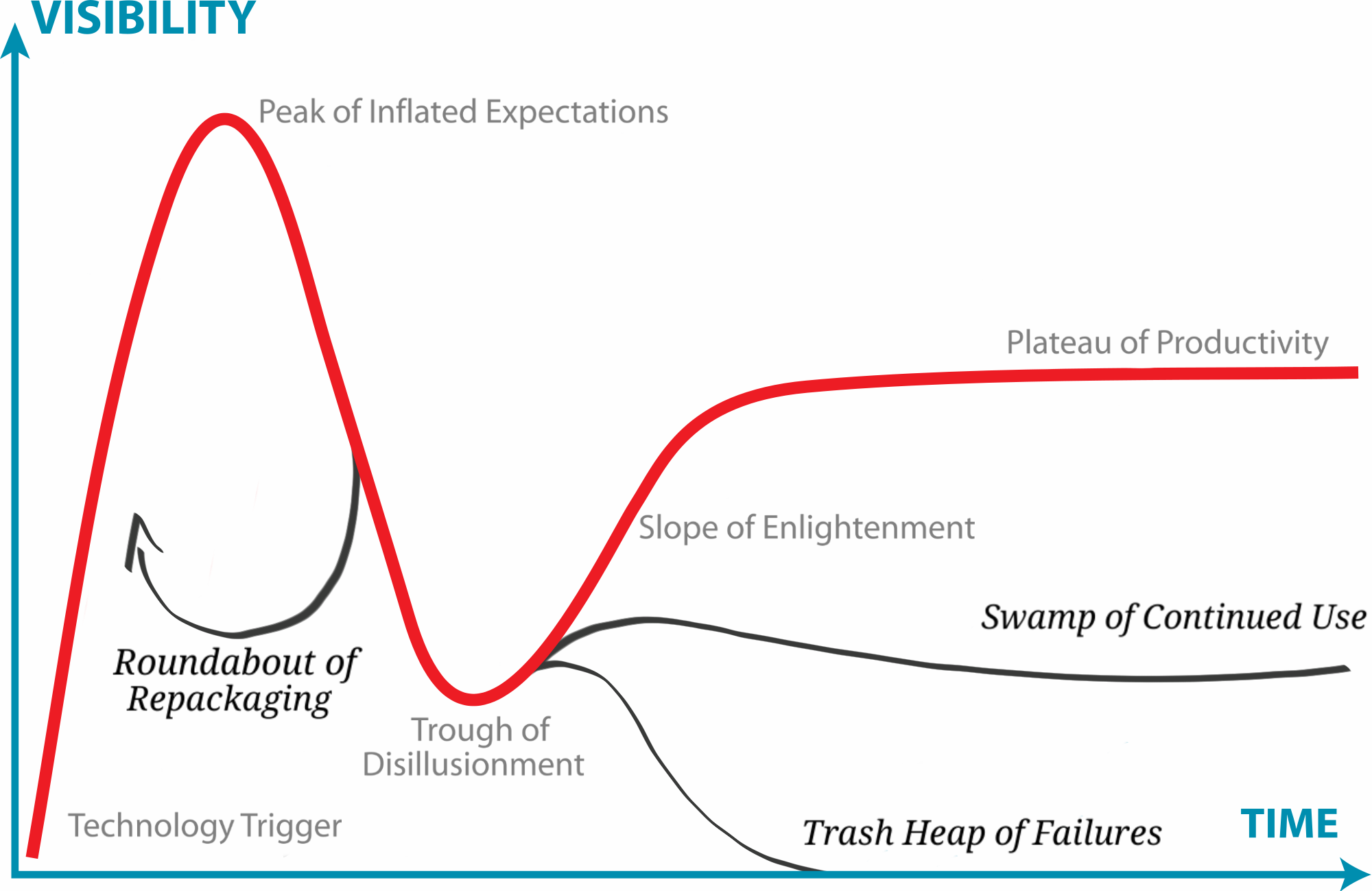
But also, nothing changed. We're still using a keyboard, or a virtual one. We're still running UNIX everywhere. We're still coding with vim. We still have to fight memory leaks. We still want more power, more colors, more bits, bandwidth and whatnot. And we're never satisfied with what we have.
Technology will come and go. Sometimes it will stick, but most of the time it will die. Being a developer over 40 is like being a developer of any age. You've just seen more of the same stuff.
Focus on learning the fundamentals. The most basic layers are the one that won't change. Network, Security, Performance or UI. All those aspects of tech have very deep roots that we have to acknowledge and understand. They won't change anytime soon. The rest is the same wheel constantly re-invented.
Dev/Ops, one year later
The last tech talk I saw was done by Aurore and Pauline. Aurore is a Dev, Pauline an Ops. They shared the story of their project, of how they had to make their two worlds collide to better work together.
Aurore works with 10 other Devs, while Pauline is the only Ops. They had to develop and push to production a large scale e-commerce website (23 countries). Because they started from scratch they could go with a pretty nifty stack of Symfony, VueJS, MySQL and ElasticSearch (for the Devs), and AWS, EC2, Varnish, Terraform and Packer (for the Ops). Both teams worked with Git, Travis and Docker.
In the talk, they shared 4 real life stories that happened to their project and how they solved them. All issues had a technical cause, but were solved by a social solution.
The first story was about how they had to update their DB with the latest dump from the company CRM every day. The Devs coded a script to import the CRM dump into the DB and asked Pauline to put it into a CRON to be run every 24 hours.
Several days later they spotted a big issue in production. All their products were displayed twice. Turns out they were stored twice in the DB. The first time it happened they thought it was a flupke in the script and re-pushed all the data. The second time it happened they started investigating more thoroughly.
It took some time for them to understand the root cause as the bug only ever occurred in production and randomly. After a while they understood that defining a CRON on a machine in a Blue/Green environment was not a good idea. It was not one machine that had the CRON on it, but actually two of them, resulting in the two pushing their data to the same shared DB everyday, at the same time. Most of the time, it was invisible (one machine was overriding what the other just pushed), but sometimes, race conditions appeared and the data was saved twice.
The solution here was to update the script so it's aware of the environment it was running on. That way only the script in the active environment would proceed.
The whole issue could have been avoided if, instead of going to Pauline with the "solution", Aurore would have explained what she wanted to do. They could have then found a solution together. This advice actually works in every situation. Don't force your "solution" into people. Express your need and listen to the other person need. You'll find a real solution that way.
They realized that their teams had different objectives. Devs were working in a scrum environment, where they had to deliver new features every week. The Ops goal was to make sure infrastructure was stable. Less deployments means more stability. They had conflicting objectives, but understanding the other side goals makes you design better solutions.
They also realized that both sides were missing part of the picture. Devs had only a rough ideas of the differences between environments. They knew the theory, but didn't understand what it implies for their code. On the other side, Ops had no idea what new features were added in the new container image they pushed to prod, nor how it will impact the topology of their network.
Both parties needed to better understand what the other was doing, because it had consequences on the way they worked. It's also true when errors occurs in production. Ops can identify which part is behaving badly, but they don't know the product nor the language enough to debug it. On their side, Devs trusted their tests, and assumed that everything was going to work ok in production.
Well, production is never the same than pre-production. You can try to have a pre-prod as close as possible to the production environment, but there will always be differences. Monitoring and reacting to production issues is paramount.
They decided it was important to allocate Dev time to help the Ops when errors in production occurs. In Scrum terms it means that story points were allocated to those emergencies, and taken into account in the planning for any given week. It was an insurance that, if something bad happened in prod, both a Dev and Ops could go fix it together. This live peer-bug fixing helped them reduce the time required to recover as well as increasing the product knowledge of each side.
As they say:
Better to have a website with 50% of the features that works 100% of the time than a website with 100% of the features that works 50% of the time.
The 7 advices they got out of this collaboration are the following:
- Automate everything. If you have to do the same task twice manually, automate it for the third time.
- Work on the same floor. If Devs and Ops are in two different buildings or stairs, they won't communicate and rely on (wrong) assumptions. Keep them close.
- Debug together. When an error occurs, put all hands on deck. Have Devs and Ops work together to understand and fix the issue. Don't keep them in the dark.
- Talk about the needs, not the solution. Don't have Devs go to the Ops saying "I need that", nor have Ops going to Devs saying "Do it that way". Talk about what you need, and find a solution that takes into accounts both parties.
- It's ok to fail. It's a tech project, it will fail at some point. It's ok. Learn from it, and go back to 1.. Automate so it won't fail in the same way twice.
- Know the differences between environments. Make sure everyone knows how local, testing, pre-prod and prod are different.
- Celebrate Success. Things will go wrong and it will take most of your energy when it happens, so take the time to celebrate milestones when they go well. It will help you move forward.
It was an incredible talk and I highly encourage you to watch it. Both Aurore and Pauline are incredibly skilled and humble at the same time. It was probably the best DevOps talk I ever saw.
Conclusion
Even if I didn't see that many tech talks, the one I saw were both interesting and a valuable use of my time. You can go to MiXiT and have the perfect blend of tech and non-tech talks.
Want to add something ? Feel free to get in touch on Twitter : @pixelastic