09 Jan 2018To kick start the new year, last Tuesday was the first session of the HumanTalks Paris meetup. I am one of the organizers of this meetup, but this time I sat in the audience, took notes, and decided to share them with you.
HumanTalks meetups are taking place every second Tuesday of each month. They always feature 4 talks of 10 minutes, followed by 10 minutes of questions. Most of the talks revolve around what could be of interest to developers, or to people that work with developers in a broader sense. Last night we had an introduction to React Native followed by another talk showcasing a real-world implementation, an explanation of atomic design principles and we finished with a high-level overview of microservices.
Evert month, a different company hosts the meetup. This time it was Onepoint, and the place was gorgeous. If you were not there, here is what you missed:
5 pre-conceived ideas about React Native
Nicolas is a mobile engineer at BAM. When they started, they were using Cordova to build mobile apps. Cordova embed a webview inside a native app, allowing you to code in HTML/JavaScript/CSS just like on the web. It kinda works, but does not feel native.
They then moved to React Native, and he demystified what React Native is really about. It's based on React but instead of having components rendered as HTML, they are rendered as native elements. Basically, instead of using HTML tags like <a> or <div>, you would use <View> or <Text>.
Because it's not really native, you could think it will be less performant and smooth. That's not even true. As the end result will always be native components, you have no performance issue there. Where you can have bottlenecks is mostly in the React part, just like any other React application, but is not tied to the native implementation. Large companies like AirBnB or Wallmart are doing their mobile apps using React Native today.
Being based on a JavaScript framework, you could think that it will die in 2 months when a new shiny framework will get released. Well, it's impossible to know for sure but there are currently 27 active committers on the project and it is officially backed by Facebook, so those are good signs that it's here to stay for a while.
But is it mature enough today? Well, there is a new version released every month, with breaking changes. They add support for new devices regularly, so it means it has an extended compatibility. The downside is that upgrading to a new version every month is painful. It should get better, with less frequent releases and breaking changes, but today the road is still a bit bumpy.
But the very good sign is that it uses the exact same ecosystem than React, so every library that works with React will also work with React Native. In addition to the already large list of available modules for React, the React Native community is also quite active and you can find ready-to-use modules for many interaction patterns already. Also, because it is a layer on top of native components, it means you can still use native components directly, so it's easy to integrate your own external SDKs.
If you've read this far, maybe you're now convinced that React Native is a tech worth trying. Best ressources to get started are egghead and the official tutorial. The basic tooling also come with a live reload that works with the native Android/iPhone emulators.
Recruiting React Native developers today is not easy though. The tech is quite recent, so it's easier to hire React developers and train them to learn React Native. The jump can be done in ~3 weeks. You can also train an experienced JavaScript developer to React Native directly.
I liked this talk because it was clear and to the point. I didn't know much about React Native before, and I feel I now have a better understanding of how it works, what it does and what it doesn't. Special kudos to Nicolas that prepared this talk in one week time!
E-learning without Internet
The second talk was a perfect segway as Richard talked about an application he wrote in React Native.
The application is called Chalkboard Education, and is a way to give offline access to university courses to students in Ghana. There is not enough room in the universities of Ghana, so only 1 out of 4 student can get a seat. Almost 50% of students have a smartphone though, but internet connection is unstable and expensive.
The goal of the application is to give students access to the courses directly on their phone, even with no connection. The app uses a Symfony backend to store all the actual content (and where administrators can add new courses), and the front-end is a PWA done in React Native.
PWA is not a new language, it's a set of best practices to have mobile web applications behaving like native applications. One of those features for example would be to be able to add an icon on the homepage to directly open the website/app.
A majority of the students are using an Android phone, which is fortunate because most of the PWA features are actually available on Android. Going for a PWA also allowed the developers to quickly ship new version, not having to deal with the hassle of submitting an app to a proprietary store.
Even if the Symfony backend exposes an API, the app does not follow a traditional API-centric approach, where each page has to request the API to get its data. Remember that connectivity is unstable and expensive, so they'll want to limit calls and have the best offline experience.
The first time you open the app, it will ask the API for the list of all courses available. At that point it will download all the metadata (the name of the courses), but not its actual content. The user will be able to navigate through the list of all available content, having a first glimpse of what will be available.
In the background, the application will download all the text and images, displaying a small progress bar. It does not block the user, they can still browse and access the content as it gets downloaded. Once finished, the user can turn off the connectivity and have access to everything.
Text are stored in localStorage and extracted when needed. Image requests are intercepted by service workers and returned from cache instead of hitting the network.
They even managed to handle the student progression through SMS. Whenever students finished a course, they could validate it by sending an obfuscated code to a specific number, and they would get another code in return that they could enter to unlock the next part. All the content is actually already downloaded in the app, but is unlocked when the correct code is entered.
This was a nice and clever use-case for an offline app, using tech to bring knowledge to people!
Atomic Design
The following talk was another talk by a BAM employee. Thanks to them for filling the missing speaker slot so quickly! This time it was France, a mobile app designer that gave us an introduction to atomic design.
The classical workflow for designing apps is to first think about the user journey, then map each step of the journey through wireframes, transform those wireframes into mockups and then hand it to the devs to integrate.
It works well, but it forces everyone to think in terms of pages. Each step is a page, and each page has to have its specific mockup. It creates a lot of duplication because for a simple login form, you have to create a mockup for the login, another for the signup, and handle when the inputs are empty, when there is an error, etc. Just like duplicating code will lead to more errors, duplicating mockups will also lead to inconsistencies.
The problem is even more visible when various states of an element have to be created. In a long form for example, including checkboxes, tooltips, error messages, notifications, etc. you can either create a new mockup for each state, or create a meta-mockup with all states at the same time. The first one is time sink, and the second does not represent reality.
Also, by forcing yourself to think in terms of pages, you lose some cohesiveness in your app. You can make very nice looking pages, sure, but the last you created will be very different than the first one. It will become a frankenstein monster of different styles at the end and your users will feel confused. Repetition of common patterns will create a sense of familiarity to your users, and once you have familiarity, you build trust. If each page of your app is different, you'll lose credibility.
So, what is atomic design and how does this solve this issue? The metaphor comes from the atoms, being the smallest non-breaking element you can have. You can't go smaller than that. In design those atoms are things like font name, margin size, colors.
Those atoms you group into molecules: input fields, buttons, links. And those molecules, you group into components: login prompt, comment display, notification bubble. Once you have those components, you can mix them to create your pages.
This list of atoms/molecules/components are gathered into a styleguide document, shared with the team, and that they can use to build pages. It will help the designers' life, because they will have a source of truth, a list of words they can use in their visual sentences to build pages. But it will also help developers, when confronted to a page that was not planned by the designer, they'll be able to pick one of the existing components (or build their own using the existing molecules).
The approach seems to make a lot of sense, and France was able to explain it clearly on stage during her presentation as well as during the Q&A session. I still have a few questions about that though: like who is responsible for keeping the styleguide up to date, and what form should the styleguide have (should it be an online document or should it take the form of a CSS framework for example?).
Microservices architectures
The last talk was more high level, talking about microservices architectures. I've seen a lot of talks about microservices in the past, and a lot of them were filled with buzzshit (a mix of buzzword and bullshit). This one was very different. I learned a lot.
Microservices archictures were first conceptualized in 2014 by Martin Fowler. Every 5 years on software development, we have someone explaining how everything we did in the past 5 years was dumb, and what the new way should be. Microservices new way is to get away from the monolith app and have several small services, each focused on doing one thing.
Microservice should be deployable independently and automatically. Having small services also makes scaling easier. You no longer need to replicate your full monolith app several times when what you only need is scaling a specific part of it. It will also help you deploy new features in small increments.
The language used for each microservice should have no importance, just use the right tool for the job, and don't bother about having a uniform stack. Having different languages will mean you'll be able to add new components when the need arise, and use the best tech to do it. It makes recruiting people to work on them way easier than having to recruit for an old tech.
The hardest part of microservices is finding the right size. You want to avoid both nano services (that only hold one method), as well as macro services (that are more akin to god objects doing everything). You have to split them by business logic, and you'll have to think carefully about that. You should definitely not split by language.
Microservices will communicate through APIs (REST most of the time, but it's not a hard ruling). APIs are code interface, but you will also need a lot of human interface. Each team will work on a specific microservice and they'll have to work together to make it work. Following Conway's law, your microservices architecture can only be as good as your inter-team communication.
But one essential point of microservices is that you should start using them only if you have some requirements in place already. Because you'll now have much more services to deploy, you need to have a way to ship quickly and in a reliable way. You need automated monitoring, testing, and deployment before you even start splitting your monolith.
Having so many moving pieces will also force you to think about errors in a different way. Errors will no longer only happen inside a service, but also in the way they communicate. Each call can potentially fail, requiring you to have an overview of all the calls and handle the failovers. Tools with a Chaos Monkey approach can help you have a better understanding of what can go wrong.
The talk was packed with content. Mahdi only managed to cover 1/3 of all the slides he had prepared for the talk, and doing so at fast pace already. It might not have been the best introduction to microservices if you never heard about them before, but if you did, there were a few nice nuggets of information inside.
Next month
Next month we'll be hosted by BlaBlaCar. Hope to see you there!
06 Dec 2017Yesterday was the DevRelCon London conference. One full day of talks for people doing Developer Relations. I went there for the first time last year, while I officially started to work as a Developer Advocate.
It was highly refreshing to see so many people actually doing this job, and realising that we mostly faced the same problems (explaining our job, getting metrics, learning to say no, managing our inbox, etc). But most importantly, seeing that no-one had any idea of what they where doing was highly refreshing and mad eme feel much better.
The job is young, we're still learning, we're all doing the same mistakes. Such a conference is the best place to share them and learn from each other. This year was no exception. I did learn a lot, and got a few new questions to think about. Also, being in the audience, instead of on stage, absorbin knowledge was a great change of pace.
Opening talk
I arrived a bit late in the morning and the first talk had already started. As it did not had slides, I had a hard time understanding the content and the message. To be honest, now that I'm writing my notes down, I don't actually remember what it was about. There were so many great talks during the day, if I don't have a visual cue to remember them, I'll just forget. Funny how the brain works.
Making the imlicit expliti
The actual first talk I saw was by Erin McKean. She works at Wordnik, and online community dictionnary. Her talk was about the similarities between being a dev advocate and being a lexicographer.
In both cases, you're asking yourself the same questions: "What do people know? How can I teach them what they don't?". This field of study even has a name and it's called epistemology. It means it's the study of knowledge: what is knowledge? how do you acquire it? why do you know what you know?. Very interesting subject actually.
As dev advocates, we're doing talks, building demos and writing tutorials. We have an audience that wants to know things, and part of our job is to teach that to them. When someone comes with a question, we're here to answer "I can teach you how to do that.".
This very simple sentence actually hide a lot of complexity. Who is you? Not everyone is the same. What does how means? There are various ways of doing the same thing. And finally what is that? What do you actually want your reader/audience to learn?
Being a developer advocate is actually nothing more than being an "applied epistemologist". That would look fancy on business cards, but is true.
When you start thinking about your audience, you might want to generalise to "I speak to developers.". But not two developers are the same and they have various degreers of knowledge, and past experiences. Some learned to code at school, other learned on the job and another chunk actually are self-learners. The last group is interesting because the did not actually learn by themselves, they learned by looking at what others where doing, and replicating it, or reading blog posts. They were actually taught by the community.
It's important to keep this distinction in mind when you write content. Don't assume that your reader learned the same things as you in computer science class. Maybe they never had computer science classes (I know I hadn't).
Another aspect is that what you want to teach your audience might be different from what they want to learn. You might want to teach them how to use an API, how to monitor Docker in production, what is a monad or anything else related to your topic. But what they want is actually broader than that. They want to become a better developer. They want to get better at what they do.
You cannot just teach them a new tech in a vacuum. Your tech will interface with other, real-life, elements of the stack. You shouldn't isolate your example into the ideal world where your tech is the only one. Real-life projects don't work like this. You might need authentication, monitoring, automated tests, and so on. It's not enough to tell your users "Obviously, you shouldn't do that in production that way", without providing an alternative or at least explaining why. If you don't explain, people will not understand the consequences and will do it anyway.
Building a demo that does search and authentication and image resizing and monitoring and rate limiting and many other things will surely be too much if you only want to showcase the search part, though. You don't have to dig deeply into the others parts, just show that they exists and just do the minimal part so the audience can fill the void. The important part is not to pretend that other parts don't exists. Acknowledge them, and give pointer and simple examples on how to integrate with them.
As someone was saying, "All models are wrong, but some are useful". In DevRel it's similar. All our tutorials are incomplete, but some are useful.
You want to transform a tutorial about your API into a teachable moment. You should not try to teach them only about your product, you should be here to help them get better at what they are doing. Sharing tips and tricks with your tech, but with other tools as well. You want to be a role model, to lead by example.
But try to not be put on a pedestal either. Don't try to hide mistakes you do. We all do mistakes, that's how we actually learn things. We your live-coding sessions fails, show how to fix it. Don't pretend your way of working, your choice of tools, are better than another choice. Just explain what you use, why and how, and everyone will get value from that.
The overall talk was really well delivered, with some valuable nuggets of informations. The introduction and first half were really attracting for me, I had a great time watching. The second part was more a list of tips and tricks, but I felt it slightly less inspiring.
DevRel leadership
Second talk was by Ade Oshineye. He talks about the hard questions that are often asked to DevRel people. Who are you and what do you do? Instead of answering, he often asks the question in return, to know how people perceive our job. None of the answers he got were actually incorrect, but they failed to paint the whole picture.
"You do hackathons and go to conferences". Hmm that's right that we do this. "You blog and you tweet". Yes, we do that as well, but that's not a goal. "Oh, you're the rockstar developers". Hmm, I think you mean that in a positive way, but that's not even true.
Overall DevRel is victim of a Cargo Cult. Many successful companies have a DevRel team, so when company reach a certain size they think "Hey, I need a DevRel too!". So they hire someone and try to replicate what others are doing, but without understanding why they are doing it.
DevRel is a bi-directional activity. We're an interface between the outside world and the internal employees. The outside world is full of people in varying stage of commitment. Some know about our product, some don't, some like it, some don't. Our job is to make sure informations from one side can correctly go to the other side, and more importantly to the relevant person on the other side. I would even go further as to say our role is not just to be an interface, it's to ultimately disappear so both sides can communicate directly.
Now what does it mean to be a leader in DevRel team? Even if he has been doing this job for 10 years now, he is still unsure of what he is doing. DevRel is a young field. It evolves quickly and what you do one year might not be valid the next. This is true both because the industry as a whole evolved quickly, but also because the company where we work also evolves.
What a great leader should do is being able to articulate the team purpose, or mission. What are we doing? Why does the team exists? Why does it matter? Why should we keep existing? Those questions should be asked regularly, because answers will evolve. The moment you stop asking yourself those questions, your team will die.
Just like teach a tech in a vacuum does not make sense, the prupose of the DevRel team cannot be defined in a vacuum. DevRel touches on so many different other teams that our purpose is shaped by our interaction with those teams. It is also shaped by the other organizations in the ecosystems, partners and competitors alike.
Are we here to drive adoption? Or should we help improve the quality of the product? Both questions, and many others, are completely valid purposes for DevRel. The important part is that the mission should be clear, and that ideally every team member believes in it. It does not mean the mission should not evolve in time. Actually it must change over time.
To define your mission at any given time, we should look at the various points of leverage. By that he means the points where we can actually make a difference if we intervene. We should identify them and it will help us prioritise what we do. The way he suggested looking at it was to look at the maturity of your product.
When the company starts, the goal of DevRel is to do some outreach, letting more people know that we exist. It includes goings to meetups, hackathons and conferences. We have to show that we exists and stay top of mind by being present in various events.
When the company grows, this part starts to become less and less scalable. There are so many events every day all around the world, we cannot get to them all. So we start building content that scales better: blog posts, and tutorials, and demos, and documentation, etc.
But even with the best documentation, you'll still end up with people having issues, and asking for support. The bigger your outreach, the more support channels you'll have to handle. In addition to your official support email, you might have a community forum, questions on stack overflow, issues on GitHub and also a lot of other people asking questions about your product in channels you're not even part of (like Slack groups). Making sure you help all those developers be successful is a lot of work.
Then as you grow even bigger you start creating partnership with other companies and platforms. Maybe you have an official training so people are certified users of your platform, or you have some agencies you trust into building quality implementation and you can offload some of the support to them. At this stage, you are now building relationships with C-level positions, which is whole different new set of skills.
All of that makes what DevRel is about. But you cannot objectively expect someone to go to events all around the world, answer support questions on a vast array of channels, while maintaining a deep knowledge of your API and securing partnerships with other large companies.
Each of those steps requires commitment, it require to devolve a large amount of time to get to know the communities and build the needed trust. One person cannot do all of that. When your company evolve, you'll end up doing very different things. This might not be specifically in that order, but the reality is that what the day-to-day job is will greatly change.
This is important to keep in mind for your teammates. We all want to grow in our job, we want to get better, we want to learn new things. But what if I like going to events and don't want to write tutorials? What if the next step is not appealing to me. Will growing in a DevRel team will make me feel better or worse?
Slight disgression here as the speaker did not mention that part, but I wonder how geographical separation plays into that framework. Your product can be particularly well-known in a specific region and not at all somewhere else. Should we start the process from scratch with meetups and events in the new region, or can we jump directly ahead?
Ok, back to the original talk. Some interesting metrics the speaker gave on how to gauge the mood of the team is to ask team mates regularly to estimate, on a scale to 1 to 10, how happy they are with their job. The actual value does not really matter, but variations over time will tell a lot.
In the same vein, it is also important to ask the leader to regularly put on a scale to 1 to 10 how happy he is with the results of the team and with every individual. Once again, absolute value is not very important, but variations and trends will tell a lot, especially when confronted with the happiness of the person directly.
He finished his talk with this story: One night when walking home, a men met another met in the street. The second man was obviously looking after something he had lost on the street floor, under a lamp post light. The first man asked the second - "What are you looking for?" - "My keys." - "Where did you lost them?" - "Over there, on the other side of the street." - "Why are you looking for the here then?" - "Well, there's no light on the other side of the street, I would not be able to see what I'm looking for."
This story had a lot of echo about what we do in DevRel. DevRel is very hard to objectively quantify. Some things are really important and must be done, but are even harder to measure. Often, we look for the comfort of clear, quantifiable metrics, to have the sense that what we do has value. We tend to do the visible and easy stuff because the important stuff is too hard to quantify. Knowing how many people read a blog post or how many retweets we have has value, but it is a very indirect metric of what is actually important.
This talk was one of the more interesting of the day for me. There were a lot of great insights, and hearing someone else put words on the struggle I'm facing helped a lot into seeing I wasn't alone and that it was actually normal that this stuff was hard, it wasn't just me.
Better DX messages
After lunch break, I had the chance to catch the quick 10mn talk about a better way to do the DX of error messages.
Every developers that is going to use your API will have error messages returned to them at some point. The quality of the DX of your error messages will have a direct influence on if this same user will move forward or not. Errors are a blocking point in every developer's journey. It's the moment where they can easily decide to stop trying your API.
The worst error message is the one that does not say anything except "An error occured". Slightly better is the one that is telling you that you forgot parameters, without specifying which one.
Better error messages are the one that will tell you why an error occured, and how you can solve it. As Developer Advocates, we've used our own APIs hundreds if not thousands of times. We know the common errors and pitfall. We should help define error messages (either directly in the API or in the integrations around it) that will give pointers to users on how to solve them (did they add their API Key? Does it have the correct permissions? etc).
The UX of DX. User testing in the invisible world of API
Following this talk about errors, we had another one about the UX of DX. The point was to show that it was not because an API had no UI component that it could not have an actual UX. It's not because you're a developer that you don't like easy to use tools. You don't need a UI to have a UX, API are actually interfaces as well, it's even in the name!
As Developer Advocates, we are using our own APIs every day. We know them by heart. We know them so well that they now seem obvious. It means that we are not the best suited to help improve their UX. To improve the UX, we need to do user-testing with people that will bring a new fresh look.
Ease of use of an API is a strong selling points. More and more companies are releasing APIs. Technically, there is not much difference between Webtask.io and Firebase functions. Stripe and Payfit are similar. SendGrid and Mailjet do similar things. Sure, there might be some feature differences, but you'll only notice them after you've become an active user of them.
While when it comes to UX, that's actually the first thing you'll see. If I have to add a payment API on my website I'm going to check what is available, and I'm going to implement the one that seems the easiest to implement (in that case, it will be Stripe). UX of your API clients (or DX, as we call it at Algolia), is a strong differenciator.
At Algolia, we try to build the best DX possible in both our API clients and documentation. I often say that "because we are developers ourselves, we know what developers wants". This talk made me realise that there are so many different kind of developers that we don't actually really know what they each want. Every developer will come to our website looking for a different piece of information. They will be looking for the information that will solce their needs.
We should start every DX improvement idea by asking actual, external, developers what they are looking for. This phase is an exploratory one, where we'll talk to many different people, and have no idea what we are going to discover.
More than talking, we should also try to turn those discussions into something visual quickly. The same word can have different meaning for different people. Visual representation (it can be as simple as pointing things on a website) will get much better result, making sure we're talking about the same thing.
The next step of reworking the UX of an API is naming things. This is one of the harder things to do. You want to find some naming consensus where everyone somehow understand the gist of what one word is supposed to represent.
A good way to test that part is to write down all endpoints of your API on various index cards. You then give a scenario to users and ask them to order the endpoints in the order they would call the endpoints to validate that scenario. If users are struggling it means that either your nouns or verbs naming choices are not obvious enough. Try removing an index card and replacing with another and see if it clicks better. Using index cards, you can iterate quickly on that, without having to implement anything. Don't overdo it. Your cards should look ugly. If it's too beautiful people will give you less honest feedback, while if it's cheaply done they will be more direct.
I found the next step to actually test this workflow extremely clever. You put a developer and a test user in two different rooms, but both connected to the same slack channel. You then ask the user to redo the scenario, but this time by actually sending messages through Slack to the developer, along with all the required info. If the developer can actually reply to the request with the specified information, then your API is making progress. Such a test will allow you to quickly show what is missing and if the flow of requests/responses makes sense.
All those examples looked like a very interesting way of creating an API with quick iterative sessions, without drowning into endless specification. Adding those findings to an existing API can be trickier because you'll then have to introduce versioning in the API. If, like use, you've decided to always stay retro-compatible in order to only have one API version, that will be harder.
But the advices where really great, and I think that's something we should be doing for upcoming new features or endpoints (or even for secondary APIs like the logs or monitoring). I wonder how it translates with other APIs (like library and frameworks API).
Overall a very hands-on talk. Something that I think could fit into a WriteTheDocs or any dev centric conference as well. Defining API endpoints is not only the job of DevRel.
Live API Teardown
Next session in the same room was Cristiano Betta doing a live teardown of an API website. Cristiano has an ongoing serie of videos where he walks through the whole onboarding process of various API companies, basically doing live user-testing and putting the accent on everything that they are doing wrong.
As he put it himself, he is not trying to be a jerk in doing so, but he is not actively trying not to be jerk either, so even if constructive, the recap can be quite harsh sometimes.
For this session he put several names in a hat and picked one at random. Algolia was in the hat and I would have love to get feedback and ways to improve from Cristiano. Unfortunately, SendGrid was randomly picked up (again).
He started his journey by playing the developer that goes to the website not really knowing what they do. The home page should quickly tell you what the API is doing without you having to guess. It should also let you try the actual product without having to commit to anything.
SendGrid does a good job at explaining that they send emails. It's pretty clear from their page. Then, Cristiano clicked on the API link to see how it works. There he had a curl code snipper. That seemed straightforward so he copy-pasted it in its terminal... and it didn't do anything because the API key of the snippet was not a real one.
That's too bad because it would have been awesome if that would have worked. Simple copy-paste and sending an email. I would have been blown away by the simplicity.
Instead, it seems you have to create an account to get a real API key. They are pretty aggressive on the payed plans, but they still have a clear link to get a free account.
A simple form asking for name, email and password comes next. The name field raised a few question: why is this field needed? what will they do with it? should I put a nickname or my real name?
The second page after that was much more aggressive: first name, last name, gender, company, role, size of the company. It clearly shows this is for sales or marketing to more easily qualify the signups but the questions were so specific that they didn't make much sense. In the end, Cristiano answered everything with John Doe and Lorem Ipsum content.
This is a double lose situation for SendGrid here. They don't get any meaningful information out of it, and they have a customer that starts his journey pissed off to have to fill an fake form just to get an API key.
Next step was to send an email with the ruby gem. It worked flawlessly, a bit of copy-pasting an API key and an email was sent. The end result was impressive, but the DX could still have been improved along the way: there was no link to the documentation from the onboarding page. And more importantly, why is the Ruby gem named sendgrid-ruby? If it's a gem it is in Ruby, but definition. If I see that I assume their API clients are automatically generated and not actively maintained, which does not send a very good first signal.
Overall it was still an interesting session, even if it's unfortunate that SendGrid got the chance to get the treatment twice. I would have loved to have Algolia got through this harsh testing.
Art of slides
The following talk was another of my highlights of the day. I personnally often do talks, and I try to alway get better at the way I'm delivering the talk, both about my stage presence and my slides and this talk taught me a few very interestin things.
As I was saying when I talked about the first talk of the day: I don't remember it because it did not have any slides. Slides are a very important part of talks. They help your audience remember your points by setting a visual cue into their minds.
Slides are here to help your point across. For every talk you do, you should ask yourself: "What is the one thing I'd like them to remember from this talk?". Once you have this, you can ask yourself if what you have in your slide really goes in that direction or not.
Your number one goal is to allow your audience to absorb the information your are sharing with them. You will not be the only speaker they'll see today. You want to make it as easy as possible for them to absorb what you share. The design of your slides should help minimize the cognitive load they'll have, not increase it.
She then shared 4 principles of slide design, reminding us that this is the one she follows but that there is not "one true way" of making slides.
1. Maximise signal, minimise noise
We should try to keep the noise to signal ration as low as possible in the slides. Each slide should have only one purpose. If we want to say more than one thing in one slide, it's better to split in several slides. That way the audience will get less overwhelmed and better able to absorb the content.
If you end-up doing a bullet-list type slide, you might be better splitting them into several slides. It does not mean bullet-list are wrong, but only use them when you actually want to show a list of things as one mental object, and not talk about each of them individually.
Slides are not your teleprompter, you're not here to read them (people can read just fine). If you need to read your notes, use the speaker notes mode. Slides are here as a reminder of what you say.
She also said that slides are not meant as post-talk notes (or for people that could not attend). Slides are in support of you being on stage, they can't work without you being there to use them. If you need a post-talk support, go create on in the form of a blog post, or wait for the video.
I'm not entirely on board with that part myself. I like to be able to follow the thought process of a talk just by looking at the slides. Slides that only have images or one word per slides requires the speaker to be very very good. Today there were a few speakers doing that, I was impressed by their ability to deliver a clear message with slides being only made of a few words on a colored background.
Overall, try not to distract. Don't put too much text because people will try to read them and listen to you at the same time and will fail at both. Also, you don't have to fill your slides. It's not because you have unused space that you should fill it.
2. Make important information stand out
Based on the von Restorff effect: thing that are different will be more easily remember than more mundane elements. You just have to change either the color, size or shape of elements or words to make them stand out.
Try to pick a color palette and stick to it. Pick colors that have a nice contract so they will still be readable on a projector. You can try colorsupplyyy.com for various color combination. Try to use a dark background if possible (light background can be blinding in dark rooms). Pick a simple color for your text, and a highly contrasted color for the important stuff you want to highlight.
Changes in font can also replace changes in colors. Try to pick fonts that are not default fonts as most of the audience will be used to seeing them and it will then not stand out. Also, most basic font pre-installed on computers are optimized for paragraphs of text, and talks usually only have a few words displayed.
3. Show AND tell
A picture is worth a thousand words. Just like we said in the talk about user testing your API, try to add visual elements that might better represent your point than long and complex sentences. Great examples are when you need to show numbers, percentages, maps, timelines or diagrams. Images are more explicit than words.
Try to avoid photographies, unless they exactly convey the point you're trying to make, otherwise they might just be confusing or distracting and adding to the cognitive load. pexels.com and Flickr Creative Common search are great places to find photos. For icons, you can search on The Noun Project.
In the same vein, you can use animations if they really help you convey your point (once again, for an animated diagram for example). Animations are very easy to misuse, so be careful and only use them when they really bring something.
4. Be consistent
Being consistent does not mean every slides should look the same, but similar parts should be expressed in similar ways. For example all the slides where you have a quote can have the same styling, same for slides with code examples.
It will help your audience understand better as it will all be familiar to them. You slowly expose them to the building blocks of your design, and with repetition you create consistency, and this consistency adds to your point, making you look more professional and expert.
The 4 points were on point, I reference this presentation when I'll be helping people doing their slides. She also did not mention it, but I saw the speaker applying a few other speaking tricks with great success: adding slides to recap the important parts, repeating the important messages several times, with only slight variations, and having her intro and conclusion perfectly rehearsed.
Her conclusion was also completely on point. Great talks are not about the content or the speaker, they are about the audience: they have to teach and inspire the audience in the room.
DevRel survey
After the break, we had a small recap of the annual DevRel survey. I did not take a lot of notes, but here is what I remember.
Many in the industry struggle with mental health issues and burnout episodes. What helped them the most was spending time with family, but also learning to say no to things. I can definitely relate.
What was considered the most important part of the job was still events, meetups and blog posts. And what was considered the harder part was scaling the outreach.
Intersection of DevRel and Product Marketing
The following talk was by SendGrid, about the intersection of DevRel and Product Marketing. The title seemed interesting, but I must confess that I did not understand the subject at all. I quickly lost focus and interest, and started to look at the slides instead, trying to see if he was following the advice I learned from the talk earlier in the same room.
Answer was no: the SendGrid-branded slides were distracting, slides with a lot of text where passed too quickly, animated gif were used in place of content, and animation where used (even in a comical manner, but did not add anything). Still, there was some consistency in the slide design, but not enough to make me understand the actual content of the talk.
Still, here are some of my notes that I still find interesting, even if I don't know how they are supposed to be linked together :)
Most of us in DevRel are working alone, or in small isolated team. We are all learning the same things the hard way, doing the same mistakes and asking the same questions, but we're not great at sharing what we learn. Well, DevRelCon is actually the best place to do that. I think he talked about DevRel at that time. Or maybe it was product. I'm not sure.
Still, the one thing I remember and that actually makes a lot of sense is that DevRel and PM teams should work more closely together. We can find the perfect, committed, user that a PM would need to user test a new feature. On the other hand, we could greatly gain from knowing in advance what is going to be released and get some field knowledge about it.
Scaling without losing your soul
Following talk was by Joe Nash from GitHub, that delivered a very interesting talk packed with useful information at the speed of light. I did not managed to write down everything that was valuable from the talk, and I will have to re-watch it in video.
I won't go into all the details that are way too GitHub-specific on how the implemented it, but he basically talked about the GitHub student pack. It's how they train what we internally call Ambassadors: people that are volunteers developer advocates.
There was really too much content in the talk for me to know where to start. What I would say is that scaling a DevRel team is very important, and a great way to do it is to automate things you've already sucessfully done manually
Ground work. Outcomes. Trust: can only scale with trust. Operations: automate all the things. Iterate: start again and improve.
the need or ambassaodrd gros out o your stargegy?
SCOOP framework: SUPPORT: be there for your delopers. strip answering the same questions. can we go to every hackathons, give swag, etrc. Identify people with the same kind of needs (conferences, swag, access, etc). Give them things that can be repeatable (training kit, first time grand for hackathons)
sponsoring conferences for those people (conference for hackthon organisers). Help something that is already doing it. Like conference organisers, or MLH, canned responses.
(talk was too fast, lots of interetsing bits but too quick)
you need albassaodrd to trust in you, and want to talk about it. they won't do things you wouldn't do yourself. aambassadors should rperesnet the brand, but won't have pay for that.. Trust them to make trhe best choices, don't start to micro manager. Trust them to do the best: train them, but then let them dpo.
can askstudent spealer to replace a real employee because we trust them, then the conferenc etrusts us because we trust the ambassaodrs; This will let us say yes more often.
AMbassaord have local knowledge, people there have the knowledge, we will save time and money because those people know things we don't. we need to trust our experts and they need to trustr us
we should train them, public speaking module, code of conduct, tell them exactly what we expect from them. they get a sticker. theyr goal is to improve their community through Algolia/GitHub
"why do you think you need this? why is diversity important?" (other question forgot)
tell them why ther's here, they are smart they will uderstand, they will have a bettefunderstanding. tell them how it affects the bottom line, why metrics is important. give them the knowledge so they can take the best solutions.
some people don't need training on things they alreadt know (won't telle ameetup organisze how to organise one). We can still give them things that is valuable for them, and explain why we need them. We should also get to know what they do, get to know them as persons. Understand who they aren, tell them what we expect, gve them somethinhg valuable.
scale be usin what is already there. no synchronous training, don't scale. (how do you get to know people as person if it's async). The created some MOOC for training, with sharing knowledge. Use of course GitHub for trhis whole collaboration
This scales as you first train the first wave, and then they help each oter. Access to a private repo where the can share stuff.
badges of training, let you see where your communicty is. we know who we can rust with what. fundrasuing, public spekaing, code of conduct, etc. they will learn things that will help them individually to build a community of personal development, but will also do it for the company.
open new features o ambassadord, bete testers, they will have access to a valuable thing, but also be a beta tester that knows the stuff.
iterate on that. ambassaodrd will let us know what is often asked of them, so we can package stuff. maybe we can actuallyt start to hire them?
Winning at stack overflow
yo get points when you ask or answer qyestin that the community like, and lose them when theydon't like it
more reputation lets you do lmore things on the website. upvote or not questions, reduce ads, chat rooms, boost some answers, or hide content not interesting. reword questions and answers
might be interest to have someone to handle that, so best answers are pushed forwards
should we use SO as the support forum for product? some support questions should be aked to support, not to SO. Questions on SO are closed if they are not answered quickly, so you want to do support on it, you need to have someone monitoring it for reeal.
old questions should be updated with new information, so old questions are updated and found. need to update the old questions. but many people find information on SO about a lot of things. Need to update the links, the variables, etc. Lots of google juice on SO, importantto keep them up to date
retagging also help because people put their own tags. and with the typos on angolia, that could help.
plug question of SO directly to the support system, that's what we do => Slack and HelpScout
datas science: stack exchange data explorer. can export all information to see the number of questions, average time to answer, most regular questions, compare with competitors
see message that are more common in questions. is that working? what are the words of competitors?
you can create your own neytwork, there is one for nexmoe, one for magento, that miht helper when you have a large developer base
you can add bounties for questions, if you want people to try new feature or complex issue. you post something, and give a bounty, so developers wil try Algolia ina specific context
Proactive and Reactive DevRel
By our own Jessica West.
contrast of yellow on blue not looking so great reading notes too much, and reading what is on screenn better after the intro, but got back to scren too much hands touching a bit too much show a game of risk, because not everyin will know it nice content, but too much and hard to follow on the slides no need to say "shameless plug", explain more why donation instead of swag, nice example on too much "word" => definition read. one or twice might work, but all along the talk was a bit too stiff. Parts where was natural was much more interesting
best defense is offsne, but not work in devrel things we do is a roll of the dice, some randome and tries going to conferences is a roll of dice value is in the sequence: conferences on the same event, sequence of blo posts
we need to be more proactive everyone will ask you to do everyhtinh, from sales, culture, marketing, engineering, etc so reactive only will be doing too many difference things but no focus, and will take all our time as individual we get disctracted: writing content, writing code, doing talks, we do reactive stuff need to define what we do and what we don't do
we'll have to show execed and the budget what we do. doing a bit of everything does not work, we don't understand what people are doing, even if doing a lot of small tasks, not doing anything where they are experts
for proactive, you need to define what you do. stop sending people all around te world, just to be present. it's something you do at first, trying to be everywhere, but does not scale. works only if big team with one person focues on doing that. one event somewhere is not enough, you need several datapoints in the same area to see product. not 6 datapoints in 6 different area
Community / Code / Content create code and content, and the community will come give before asking. give 10 times before asking
do retrospectives: look back to achievement and objectives. iterate and adapt. industry is evolvig. competitor, new feature, size of company, etc. need to adapt and change the mission in an iterative manner.
DevRel Bill of rights: clear set of busines goals, well-defined place in the organization. need buy-in or support from exec. Not only a budget, but someone that is aligned with what we are doing.
metrics don't always tell the story of impact and impact is not a function of effort and time
One one must change one's tactic every 10 year if one woshes to mainta ones supriorty (napoleaon) change things, adapt, do what works, and try something different
do calculated risks in devrel. try new things: twlio an sengrind in hjackathons, sendrgid accelerator program, github student pack, algolia donation instead of swag, do something different
DevRel Bill of Rights
Anil Dash. Glitch.
used to be a coder, in a cmpany that didn't care about coding. found blogpost by joel spolsky, joelonsoftware. then founded SO and Trello
joel created a test. the joel test. set of practices to se eif an organizetion cares about their infra and ressouces needed. do you have a large monitor to see what you need to you use version control. it made a standrad of what you're looking for in organisations.
moved from undereespected to very respected. maye too much today with snacks and massages, and spoiled child stuff.
first employee ain fogs creek software, vp of devrel, but could not move forward, had to move out.
glitch, remix. here to restore ability to create stuff with code.
software is eating the worlds, developers shape culture what developers build, do, startups, change the world think of male/female radio buttons, but is actually free text, everything we do reflects culture. we can change culture and how things are seen
show first page of stripe and curl command, github as side project, twilio really easy. each is a mental milestone. this is the way it should be done. don't know it before, but know I know that this is way
why not define a standard. there will never be someone that will eb perfect to push the subject foward, so why not me? why not start and make it imperfect, and iterate. A Bill of Right od DevRel
clear set of business goals. seems obvoious but what do we do "we're supposed to have evrel, let's just hire one". not enough to achieve goals, need to have clear goals
wel defined place in the organization. engineering, mrketing, sales, other, don't know. dotted lines with everyone, no clear line. no clear budget, owner. "I want to know who my boss is and who I report to" is not unreasnabme. exactly what happened, so feeling better about that
structured way to impact product and platform. how do we move the feedback to product, having a way to impact the product. need to be part of the process to solve issues.
open lines of communication to marketing. no organization have marketing/devrell team wokring rogether, devrel is not top of mind in what they do
right tools designer for the job. Sales have a lot of metrics on everything, marketing have a funnel of everything. DevRel? just guessing. we are our worts ennemies: we have no numbers, or small ones, then our budget will get down first.
epxlicit ethical & social guidelines. setting the rules, code of conduct,
support for building inclusive community. increase creativty, strong value for company. active outreach. this is part of the work. need to reach peple that are not in our community. ths is the definition of building a community. people that we are not close to.
distinction from sales engineering.
ongoing resources for professional development. need time for resource and commit on things. need to learn the job, not just being reactive.
connection to a community of peers. talk with other people that care about that. might be the only one in the company doing that. people person, that like to talk and learn, do that as a job, but cn't talk about that with coworkers. will quit. job, or profession. need to talk with other people outside of company.
devrel should be a way to move forward, not moving out to grow. this talk really had all my concerns voiced. nice to see not alone. learn new things every year. just like parisweb in the first years. new step in my career.
hn goind to uch a confernce, you also start o look at the meta. all those people usually do talk, so you ca learn how to do better talks. you look at slides, are they clutterres, whaat is tge info, do I wan to tke a picture and post it? What is the enery on stage, the voice, the posture, etc. Which talks will I rmemeber at the end of the day, and why?
mixed audience and speaker between male and female
(gh-polls for polls in readme)
cold rooms, much better access to food than the long queues nice vibe of friends getting together. might be intimidating for people coming by tehemselves (getting into a new famly and its private jokesà, but once you start knowing a few people, it's atually a nice way to get introduces to more people
(Honestly, I'm really thinking about the future milestones. Pick stuff you'd love to see happening. Dreams. community events, people talking about us, speaker at big conferences. Note them in advance and serendipity wait for them to happen. Do your best, but do not focus on the goal, focus on doing the right thing, the outcomes will happen)
"I asked 6 times, I don't want to micro manage"
20 Apr 2017Here is my second post about the MiXiT conference. The first post was about everything non-tech at MiXiT, so this one will go the more tech route. MiXiT is a multi-track conference, with non-tech keynotes and random talks (where you're assigned a random room to see a talk you don't known anything about). You can spend two whole days without seeing a single tech talk if you'd want.
Streaming API
My first tech talk was by Audrey Neveu, about realtime applications. She did an improved version of the one I saw at BestOfWeb last year. Unfortunately, the gods of live coding were not with her. The drone she was supposed to fly refused to connect to the wifi. She had to raise and lower it by hand, which was funny, but not exactly what was planned.
She talked about the importance of real time. We react differently to things that moves. Our reptilian brain is wired in such a way that if it moves, it's either:
- Something we can eat
- Something that can eat us
Either way, better keep an eye on it.
Same principle applies to screens today. We're drawn to screens where things are moving. We expect data to update itself without any interaction from us. We all know the frustration of having to press the Refresh button. The Refresh button is the bane of all interactivity.

We invented the SPA (Single Page Applications) as a way to develop apps that didn't require a Refresh button. The front-end is made of HTML/CSS while the data is fetched through JavaScript calls to APIs in the background. By adding a bit of polling on a regular interval, we can make data update itself.
This is not real time though, as we only get data when we ask for it, but it's a good start. If we poll data in short interval (~1 second) we can make it look like real time. But this creates a lot of overhead. Even without such a short polling interval, most of the requests are wasted (up to 98.5% according to Zapier), meaning that the data we got is the same than our previous call. Nothing changed.
Sending so many requests has a cost. You have to open a new connection to the server each time, get the answer, then start again. Creating connection has a cost, both for the client and the server. That's when long polling was invented.
Long polling is a hack around the classical client/server achitecture where the server does not actually closes the connection. Instead, it keeps it open, and sends data when it's updated on its side. It's a clever hack, but it does not scale. Servers are not meant to maintain that many open connections at once.
Actual realtime solution exists, though. The more common are WebSockets and Server Sent Events (SSE for short). They are both well supported by browsers, but have different use-cases.
WebSockets uses a bidirectional channel to send events between the client and the server. It's a specific protocol on top of HTTP, so you might have to update your firewall rules to use it (which might be hard to do in some settings). It's incredibly useful if you need to build a realtime app with data flowing in each direction, like for a chat or a video game.
Most of the time though, what you need is to react to events sent from the server. Actions done by the users can still go through a classical GET request. For that use-case, SSE are a much better approach. They are classical HTTP requests sent from the server to the client, and you can react on them like you would do for any event in JavaScript. It's well supported (except by IE) and does not require changes to firewall rules.
We're so used to have real time in our applications, that not having it will be like having a search bar that asks you to press Enter to get results. We're so spoiled by applications like Amazon, Facebook or Google that we expect everything to be dynamic and to react to us instantly.
CSS Is Awesome
Then, Igor Laborie showed to a packed room some nifty CSS tricks. I've been using CSS extensively myself, but I was happy to discover some new tricks.
Following the Rule of Least Power, his goal was to show that CSS was powerful enough that you often don't need JavaScript nor pre-processors at all. His talk was a succession of small tricks to achieve more and more complex effects. Here is a small sample:
- By using
currentColor and alpha-transparency it's often possible to style a complete element with one simple color without requiring variables. - Using
::before and ::after pseudo-elements, you can add content, and by using UTF-8 characters you can even draw more advanced shapes. - Using background color, borders, outlines, box-shadows and before/after elements, you could draw many, many, many colors on one single element.
- Using a
content spanned on several lines using \a, clever UTF-8 chars and an animation let you create a nice loader. - Linking a
label to its checkbox on top of the page let you add a global state to the page. - Adding a
skew effect on a rectangle with some border-radius creates the perfect tab shape. <details> and <summary> are default HTML5 tags for a collapsible, and dialog can be used for modals (along with the full-screen backdrop with pointer-events: none.
Being a developer after 40
Adrian Kosmaczewski then talked about what it means to be a developer at age 43. He was talking about what changed and didn't change in all his years as a developer, and he did so with a lot of humor.
Everything has changed in 20 years. We now have smartphones in our pockets more powerful than the most powerful computer we could dream of. We can stream video and talk with people on the other side of the globe in realtime. We have access to all the knowledge of the world for free. We have e-cigarettes and e-books, self driving cars and connected fridges.
But let's not forget the large number of languages, frameworks and technologies that didn't work. From Angular to Sencha Touch, PDA and Mini-Discs, many tech were supposed to be the next big thing but ended up being the next big nothing. They went crashing down from the Peak of Inflated Expectation right into the Trash Heap of Failures.
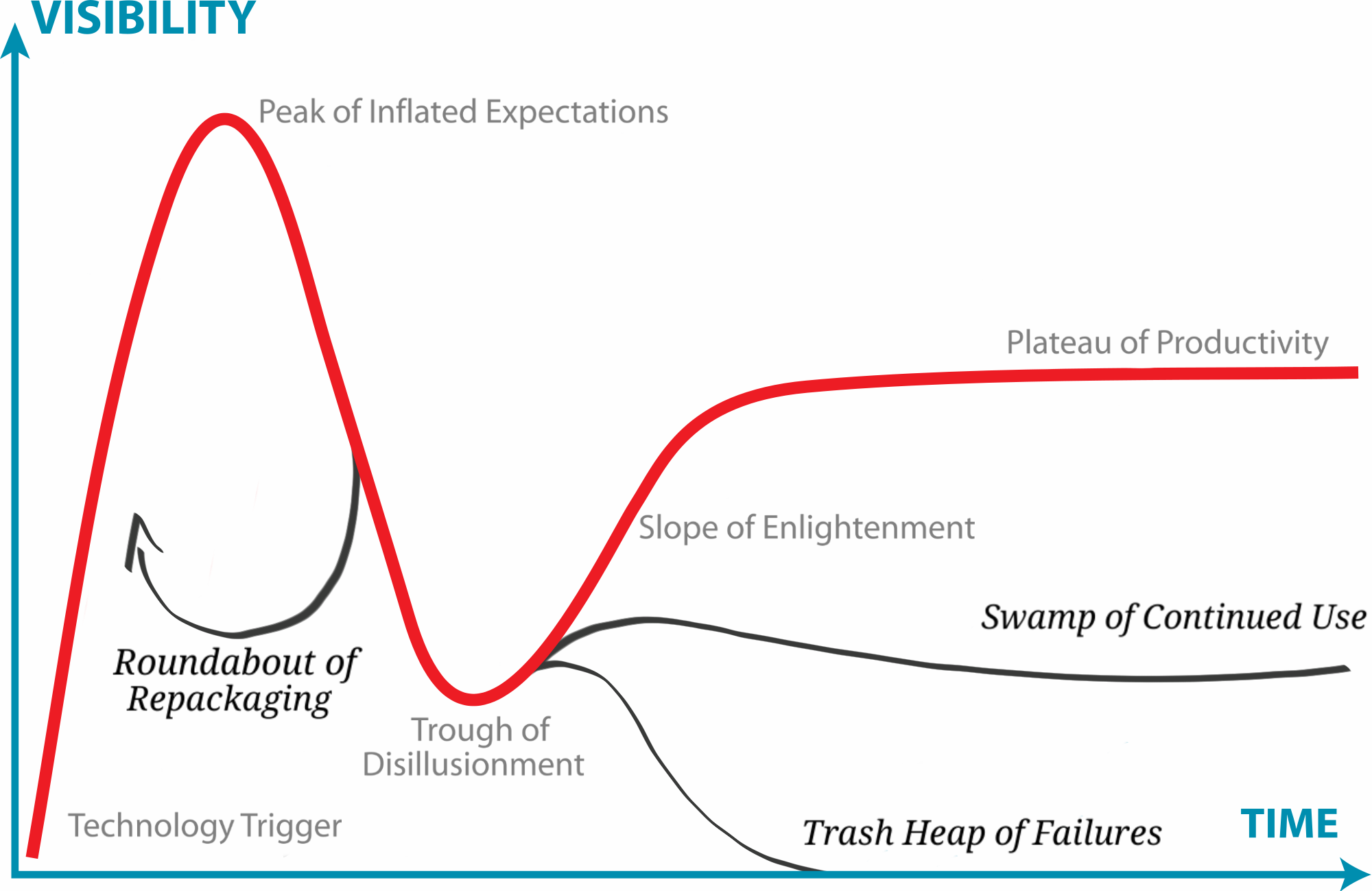
But also, nothing changed. We're still using a keyboard, or a virtual one. We're still running UNIX everywhere. We're still coding with vim. We still have to fight memory leaks. We still want more power, more colors, more bits, bandwidth and whatnot. And we're never satisfied with what we have.
Technology will come and go. Sometimes it will stick, but most of the time it will die. Being a developer over 40 is like being a developer of any age. You've just seen more of the same stuff.
Focus on learning the fundamentals. The most basic layers are the one that won't change. Network, Security, Performance or UI. All those aspects of tech have very deep roots that we have to acknowledge and understand. They won't change anytime soon. The rest is the same wheel constantly re-invented.
Dev/Ops, one year later
The last tech talk I saw was done by Aurore and Pauline. Aurore is a Dev, Pauline an Ops. They shared the story of their project, of how they had to make their two worlds collide to better work together.
Aurore works with 10 other Devs, while Pauline is the only Ops. They had to develop and push to production a large scale e-commerce website (23 countries). Because they started from scratch they could go with a pretty nifty stack of Symfony, VueJS, MySQL and ElasticSearch (for the Devs), and AWS, EC2, Varnish, Terraform and Packer (for the Ops). Both teams worked with Git, Travis and Docker.
In the talk, they shared 4 real life stories that happened to their project and how they solved them. All issues had a technical cause, but were solved by a social solution.
The first story was about how they had to update their DB with the latest dump from the company CRM every day. The Devs coded a script to import the CRM dump into the DB and asked Pauline to put it into a CRON to be run every 24 hours.
Several days later they spotted a big issue in production. All their products were displayed twice. Turns out they were stored twice in the DB. The first time it happened they thought it was a flupke in the script and re-pushed all the data. The second time it happened they started investigating more thoroughly.
It took some time for them to understand the root cause as the bug only ever occurred in production and randomly. After a while they understood that defining a CRON on a machine in a Blue/Green environment was not a good idea. It was not one machine that had the CRON on it, but actually two of them, resulting in the two pushing their data to the same shared DB everyday, at the same time. Most of the time, it was invisible (one machine was overriding what the other just pushed), but sometimes, race conditions appeared and the data was saved twice.
The solution here was to update the script so it's aware of the environment it was running on. That way only the script in the active environment would proceed.
The whole issue could have been avoided if, instead of going to Pauline with the "solution", Aurore would have explained what she wanted to do. They could have then found a solution together. This advice actually works in every situation. Don't force your "solution" into people. Express your need and listen to the other person need. You'll find a real solution that way.
They realized that their teams had different objectives. Devs were working in a scrum environment, where they had to deliver new features every week. The Ops goal was to make sure infrastructure was stable. Less deployments means more stability. They had conflicting objectives, but understanding the other side goals makes you design better solutions.
They also realized that both sides were missing part of the picture. Devs had only a rough ideas of the differences between environments. They knew the theory, but didn't understand what it implies for their code. On the other side, Ops had no idea what new features were added in the new container image they pushed to prod, nor how it will impact the topology of their network.
Both parties needed to better understand what the other was doing, because it had consequences on the way they worked. It's also true when errors occurs in production. Ops can identify which part is behaving badly, but they don't know the product nor the language enough to debug it. On their side, Devs trusted their tests, and assumed that everything was going to work ok in production.
Well, production is never the same than pre-production. You can try to have a pre-prod as close as possible to the production environment, but there will always be differences. Monitoring and reacting to production issues is paramount.
They decided it was important to allocate Dev time to help the Ops when errors in production occurs. In Scrum terms it means that story points were allocated to those emergencies, and taken into account in the planning for any given week. It was an insurance that, if something bad happened in prod, both a Dev and Ops could go fix it together. This live peer-bug fixing helped them reduce the time required to recover as well as increasing the product knowledge of each side.
As they say:
Better to have a website with 50% of the features that works 100% of the time than a website with 100% of the features that works 50% of the time.
The 7 advices they got out of this collaboration are the following:
- Automate everything. If you have to do the same task twice manually, automate it for the third time.
- Work on the same floor. If Devs and Ops are in two different buildings or stairs, they won't communicate and rely on (wrong) assumptions. Keep them close.
- Debug together. When an error occurs, put all hands on deck. Have Devs and Ops work together to understand and fix the issue. Don't keep them in the dark.
- Talk about the needs, not the solution. Don't have Devs go to the Ops saying "I need that", nor have Ops going to Devs saying "Do it that way". Talk about what you need, and find a solution that takes into accounts both parties.
- It's ok to fail. It's a tech project, it will fail at some point. It's ok. Learn from it, and go back to 1.. Automate so it won't fail in the same way twice.
- Know the differences between environments. Make sure everyone knows how local, testing, pre-prod and prod are different.
- Celebrate Success. Things will go wrong and it will take most of your energy when it happens, so take the time to celebrate milestones when they go well. It will help you move forward.
It was an incredible talk and I highly encourage you to watch it. Both Aurore and Pauline are incredibly skilled and humble at the same time. It was probably the best DevOps talk I ever saw.
Conclusion
Even if I didn't see that many tech talks, the one I saw were both interesting and a valuable use of my time. You can go to MiXiT and have the perfect blend of tech and non-tech talks.
20 Apr 2017Last week I spent two days in Lyon, France, for the MiXiT ([mɪks ɪt]) conference. I was pleasantly surprised by the high quality, both of the event itself and of the talks. But even more by the high level of care of all the staff and attendees, the wide breadth of topics and its citizen and activism involvement.
You could feel the conference was for people, for human, for citizens, before being for developers. The tech skill level was also impressive, but the more impressive was how both aspects were so intertwined.
This blog post is about all the non-tech talks. I will write a tech-oriented wrap-up soon and link it from here.
Group dynamics
The first talk set the tone (pun intended) for the day. When I entered the main auditorium, I discovered a live classical orchestra on stage. The conductor talked about band dynamics, and its influence on the rhythm.

He never explicitly stated it, but I could not resist making parallels with other kind of groups, like dev teams, or companies.
Each member of a group can be playing its own unique tune, but when put together, the melody will be even different than the sum of all individualities. Every individuals are skilled in what they are doing, and they each know what is the global melody they want to achieve as a group. They still need to be aware of the others, to follow the same rhythm. The bigger the band, the harder it is for individuals to keep in sync with everyone.
That's when the conductor comes into play. Every individuals in the group now only need to focus on the conductor and follow his rhythm. The conductor keeps track of what everyone is doing, and helps those in need, adapting the tempo so the group acts as a whole.
A good leader can let all members of the band focus on what they each do best —playing their instrument— while reducing the amount of energy needed to focus on the tempo. A mediocre leader will not prevent a skilled band to play, it will make it harder. Each individual will do his or her best, and the result will still be enjoyable. A bad leader can stall a group to a halt, where the amount of energy needed to follow the instructions is such that people don't have enough energy left to do what they are skilled at.
An inspiring talk, all in the nuances of "show, don't tell". It got my brain started, which is always a good way to start a day of conferences!
Keynotes
Other talks, especially keynotes, were centered around issues we face, as citizens, not as developers. We had talks about local currency, universal income, ethics or alternative voting systems.
Lyon has its local currency, the Gonette (as did more than 40 other cities in France). Local currency help the flow of money to stay in a local system, not leaking to more global speculative markets.

Universal income is a concept to give all citizens of a specific country a fixed income, with no requirement. Speakers debunked the classical "so even rich people will have it?", "but people will stop working!", "it's too expensive, states don't have enough money for that" questions.
The debunking I liked the most are the polls that show that when asked about Universal Income, most of the people think that the others will stop working. But when asked if they will stop working, they say no. Everyone thinks the others are lazier than they see themselves.
Ethics
Then Guillaume Champeau made me think again with questions about ethics, as a developer.
We all know that bugs are bad and we should avoid creating them. How far one should go in making sure its code is bug free will greatly vary from one individual to another. I might do TDD from day one while others might push to prod without even testing manually. When you're developing your personal website it might be ok, but what happens when you're developing embeded code for self-driving cars or planes? A bug might kill people there. How far should you go in your testing? When can you say you've done enough?
What do you do when your company asks you to develop something illegal? Or if you're sent on a mission for a company you find unethical? Coding something you know will be used to create weapons that will kill people? What about stopping bug fixes and releases on a product you know have security holes that will leak personal data? What about feeding data you know is incomplete and/or biased to a machine-learning algorithm?
What we, as developers, might be lacking is an ethical code, some kind of oath like in other professions. Doctors, lawyers, architects or accountants have to swear an oath. They are personally responsible if they fail to follow the ethical rules of their orders. We don't have those limits. We can do whatever we want and hide behind the "it wasn't me, it's the algorithm" (thanks to the complete misunderstanding of this word by media and most judges).
Trying to do our best is not enough. Even swearing an oath is not enough. Mistakes will be made, shit will happen, data will leak. Still, thinking about what we don't want to happen is the first step in finding ways to prevent it. Technology is shaping the world of tomorrow, and we are the makers of that. We have an incredible power into our hands, and not thinking about the damage we could do is irresponsible.
I don't know which rules we should abide to, collectively, and I'm not even sure rules are the solution. But we can start, individually, to think about the limits we should never cross. Let's not wait until it's too late. Better safe than sorry.
Once again, interesting questions, and my brain racing. I've asked myself those questions in the past, and came up with my own ethical lines for most of them. But I was happy discussing with more junior developers afterwards that told me that they never thought about that before and now have to find where they stand.
After the atrocities of WW2, the Universal Declaration of Human Rights was signed. It gave every individual a set of rights that they could use to oppose states. It's 2017 today, and tech companies have more power than states. Think about Facebook and Google, that have more registered users than any state, and much more information about you than any of them.

I don't act the same when I'm alone at home or with my girlfriend. I don't talk about the same subjects in the intimacy of my home, or in the subway. I don't speak and act the same way when I'm casually discussing with a coworker around the coffee machine, or on stage in front of 250 people. I might sing under the shower in the morning, when I'm alone, but would never dare do it in the street. There are things I could talk with my friends that I would not dare say if my parents could hear it, things that are private and that I can discuss with my family but would not want to share at work, or vice-versa.
We act differently based on who is watching us, who can hear what we're saying.
Now, think about everything you told Google, and if you would have ever told the same thing to your loved one, your boss, your parents, your friends or a random person in the street?
Did you search for some illness symptoms you had? Did you search for an address for a place you wanted to go to? Did you search for a political party program? Did you search for a childhood crush?
After Snowden announced that the NSA had access to this data and used it to track terrorists, people started to change their behavior. They stopped searching for some content, afraid that they would trigger something on the NSA side and be flagged as a terrorist. When Facebook announced that it could automatically detect if you were interested in some content based on the time you spend on it, people started to consciously limit the time they spent on each article, once again, fearing to trigger anything.
Knowing who is watching you changes your behavior. People act differently now that they know that what they do online is not private, and can be accessed. People are afraid they will be judged by the content they read, and that it will backfire against them.
Let that sink for a minute. People stop searching some topics, stop reading some content, because they know they are watched. Because they know they have no privacy, they're afraid of being judged by what they read, or say, so they stope reading or saying anything that is not "the norm". They stop doing in private what they would not do in public. They stop looking for information.
Without access to information, you can only make poor choices. Choice is the cornerstone of democracy; if you have no choice, you have no democracy. Removing privacy is dangerous as it removes the ability to be informed, hence to take sensible choice. Removing privacy destroys democracy.
That's exactly why, in a democracy, voting is anonymous. If voting was public, people would vote differently.
Fighting for privacy is not because people have some dark secret they want to keep in the shadows, it's actually a fight to keep democracy alive. Privacy is a mark of trust. No society can work without trust.
Majority Judgment
The keynote about the election system was perfectly timed, a few days before the french presidential election.
It started by explaining the limitation of the current voting system where you do not vote based on who you want elected, but based on how your vote will influence the result. The goal of an election is to aggregate what voters chose, in order to pick the more consensual candidate. The majoritarian representation used in France does not correctly measure opinions as it forces voters to pick only one candidate. And we don't have opinions on only one candidate, we have opinions on each of them, but those opinions are not recorded.
When it comes to something as important as picking the person that will run the state for 5 years, being asked to summarize all our views in only one name does not seem appropriate.
What is even worse is that results can be completly different if we add or remove candidates. Of course if you add a candidate that everyone loves, he or she will be elected, and the result will be different. I'm talking about adding a candidate that will not win. Just adding one into the mix will change the outcome. Why should adding someone that won't win change the final winner?
A better system would let any number of candidate take part in the election, and the exact number should not change who is winning. A way to do that, instead of asking "who do you think is the best of this 10 candidates?", would be to ask "Between A and B, who do you think is best? And between A and C?", and ask the question for each couple of candidates. Based on that we could find the candidate that is the most preferred against the others.
This system is interesing but still has one paradox. It is possible to have results in such a way that no-one is winning. Just like the Rock-Paper-Scissor game, you can find a configuration where no clear winner exists. This is called the Condorcet Paradox.
An even better system would be to ask each voter to evaluate each candidate on a specific question. Something like "For each of the following candidate, how do you think they will best represent the French interests?" followed by a double entry table with one candidate per line and columns for Very good / Good / Average / Bad / Very Bad.
The question is important, as is the wording of the choices. It is important to note that we're not asking to give a note (like a star rating), we're asking to answer a question.
It is important because it will have an impact in the way we then calculate who is the winner. Maybe we want the one that has a majority of Very Good, or the one that has a minority of Very Bad, or something different. The suggested way, called the "majority vote", is to pick the median value for each candidate (where 50% of the votes are above, and 50% are below). The candidate with the highest median will be elected. In case of ties, we keep only the contenders and do a "trim average": we remove the best and worst results of each and recalculate the median until we have a clear winner.
I really like that the way we express our choice is not boolean and have many more nuances. Finding the right way to extract one leader from all this data is tricky. If everyone plays fair, it will pick a candidate no-one really has a strong opinion about. No-one really wanted him or her, but no-ones really rejected him or her either. Is it really what democracy is about? I'm not sure, but once again it raises an interesting question.
But the best part of this voting system for me is that we can easily see if candidates are massively rejected. The vote can show that the people does not want any of them, and a new election with new candidates can be started again.
Was really everything so awesome at MiXit?
Yes.
As you can guess from this long blog post, talks of the day were highly interesting. There were many others that I could not attend, but from the short presentation we had I know there was talks about astrophysics, diversity, design, ecology or remote working.
There was one talk that felt oddly off compared to the others, about a connected green village. The subject could have been interesting, but it was presented in such a way that it was borderline cliché: TEDTalk rhythm, "inspirational video", text-heavy slides. The message was more-or-less:
We have this awesome idea, and pre-rendered 3D images of what it will look like, with happy smiling people in it.
It will be a smart village, with smart sensors, smart water pumps and smart vegetable gardens. We'll do Big Data with it, and with AI and Machine Learning, we'll make the world a better place!
Oh, and we're hiring because we have no idea how to do anything technical.

They had everything planned on several years already, and the speaker came with her own filming crew. It felt to me like a marketing stunt to have more footage for them, not really caring about sharing anything with the audience. The name of the speaker was never ever mentioned on the slides, only the name of the guy that had the initial idea. It felt really out of place compared to the others talks.
Conclusion
Many talks made me think, made me ask questions about me, about work, about our world, our society. I have many more questions after the event than I had before, and it's a very great feeling. I hadn't felt than way since the very first editions of ParisWeb. Congrats to all the team, and I'll see you next year.

06 Apr 2017Tonight was the Electron meetup in Paris. I didn't even know there was a dedicated meetup. I went there because my coworker Baptiste was doing a talk and I wanted to support him. I'm glad I went because I learned a lot.
Auto-update in Electron
Baptiste talked about one of the internal applications we are using at Algolia. The app lets the Algolia employees search into content that is spread across different other apps. Using a simple search bar, we can search in GitHub issues, Asana checklists, HelpScout tickets, Salesforce leads, Confluence pages, etc.
He talked about the auto-update mechanism. Electron apps being desktop apps, people have to install them on their machine. Developers cannot push new content as they would do for a website. They have to have an update mechanism in place, and it has to be automated because they cannot rely on users manually updating their version.
Baptiste used a system call Nuts, a node app that you can host on Heroku, and that works as a middleware between your GitHub repo (where you pushed the new builds), and the installed applications.
When the application starts (and every 5mn after that), it checks if a new package is available by contacting the Nuts server. Nuts in turn will query the GitHub repo (using auth tokens if the repo is private). If a new version is available, Nuts will forward it to the application that will download it in the background. If no version is available, nothing happens. Both those cases are handled in Electron through events fired in case of an update available or not.
Now that the technical part is over, you have a lot of UX questions to ask yourself. What do you do with this new version? Do you install it without your user knowing? Do you ask confirmation first? Do you install it right away or do you wait for the next session?
At Algolia, we decided not to install new versions silently. Most of the users of the app are developers, and they want to know when they update, and which version they are using. They don't like too much magic. From a pure debugging standpoint, it was also easier for Baptiste, when a bug occurs, to know from which version they were upgrading. Installing the update silently would have hidden all that info. We decided to display a prompt asking users if they wanted to install the update now or later.
The app itself is something you use many times a day, but you rarely spend more than a few seconds in it. You display it, you type what you look for, you find it, click it and it opens a new tab to your result. Once a result is selected, the app disappears. It means that most of the time, if there was an update, it didn't had time to finish downloading that you were already doing something else.
Prompting the user "Do you want to install the new version" while they were doing something different was too intrusive. We decided that if the app was not currently focused when the download was over, we would just not show the prompt, and simply keep the update for next time.
Next time you open the app, if an update was pending, we will prompt to install it. Once again, if the user clicked "Later", it will just ask again next time.
To conclude, Baptiste also added a manual "Check for updates" button. Electron apps really look like desktop apps, and our expections as users are not the same when we use a desktop app or a website. With apps, we want to feel we are in control. It's something we installed on our machine, so we should be able to tell it when to update if we want to. This button was not doing much more than requesting a check for update when it's clicked instead of waiting 5 more minutes, but it gave the users the feeling that they are in control.
To conclude, keep in mind that the technical part is usually the fastest. Making sure the workflow is enjoyable to your users is the hardest part. People have different expectation in desktop apps than in website. Because it's the same code for you does not mean it will be the same experience for your users.
GitScout
Second talk was by Michael Lefebvre, about GitScout, a MacOS app to handle GitHub issues. I was surprised at first that an Electron app was advertised as a "MacOS App", because Electron is supposed to be used on any platform.
I understood why they want that way. They went to great lengths to have the same kind of UX in their app as you could have on a native Mac OS app. The main example they gave is about the popover notifications you can have in a native MacOS app.
Those popovers can float partly "outside" of their main window. This is not possible in an Electron app, as an app must live inside a window, and you cannot make it go outside of it. To solve that, they created two windows. The parent one is the main app, and it has a child one, invisible by default. Then when it's time to display the popover, they will position the child window, make it visible and style it to look like a popover.
The issue with that approach is that the second window then takes the focus, which put the first window as inactive and all the OS-level styling of inactive window will take place. They then had to remove the OS-level handling of the window and redo it all themselves, so they can adjust it as needed. In the same vein, they had to deal with the clicks through the child window that should be forwarded to the underlying window.
They did a good job reimplementing the native behavior and handled many edge cases of the popover positioning. It took them about 4-5 days which would have been less more than learning to code directly in native so I'd say it's worth it... until the next MacOS update breaks everything.
Cross-platform app in electron
Then Maxence Haltel, from Aircall did a presentation about the building of cross-platforms apps in Electron. The main tool to use is electron-build, which will help you package your build for each platform.
Any platform can be built from any platform (using wine or mono), as long as you are not using any native C/C++ APIs. Also note that even if the code you write is supposed to work the same on every platform, you still have to sometimes handles the specificities of each (in which case, process.platform is your friends). Apparently, there are also some Electron-specific differences between platform, so the best way to debug is to have 3 machines, one for each platform.
All the build info of electron-build is taken from your package.json. You can define, for each platform, the specific setting you want to pass to your build. Also note that by default, only the files that you explicitly require will be included. If you need to pass any other file, you'll have to pass them manually in the config.
To release your app, you can either use Nuts like Baptiste talked about in the first talk, or use electron-release-server that you'll have to host but which will give much more power on the auth and release channels (beta, dev, prod, etc).
Audio in Electron
Last talk was by Matthieu Allegre, but about the sound APIs. Sound in Electron is nothing more than what you can do with sound in Chrome. The Chrome version being set in an Electron app, you know what will be available and what will not. Furthermore, you can pass specific flags to Chrome to enable some features.
The demo was about listing all the input and output devices of the computer, firing events when a new one was added, and then capturing the input stream of one, to send it to the output stream of another.
Aircall uses this (and then send it through WebRTC) to make calls between two peers, which is pretty clever. Having control over the environment and being able to build sound-oriented apps in Electron is interesting and I'm sure this opens the road to interesting applications. I'll have to give it a try.
Conclusion
I'm glad I came. I didn't know there was such a big Electron community in Paris (I would say we were around 60), and having that many interesting talks was worth it.